
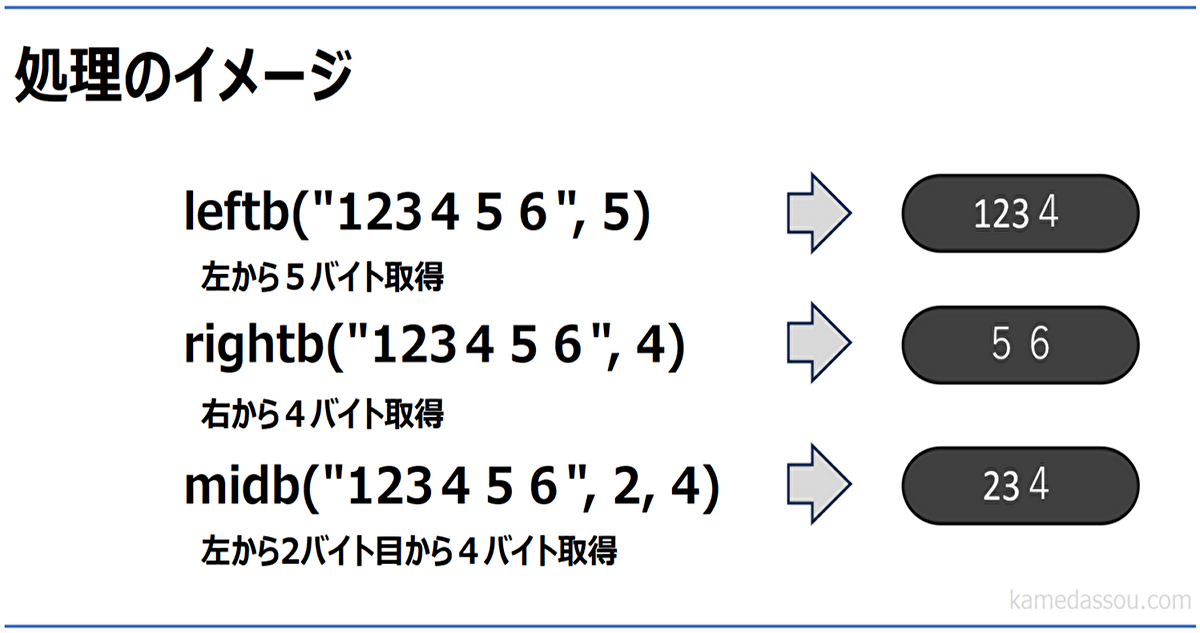
Pythonでバイト単位で文字を切り出すには?
プログラム処理中にバイト単位で文字数切り出ししたい場合がありますがPythonにはバイト単位で文字を処理する関数が用意されていません。
ですがunicodedataモジュールを使うことで同じような動作をする関数を作成することができます。本記事では、PythonでExcelのLeftB,RightB,MidB関数のように動作する関数を紹介します。
Pythonでバイト単位で文字を切り出すサンプルコード
leftb,rightb,midb関数のサンプルコードを紹介します。
midb関数はleftb,rightbそしてlenb関数の組み合わせで作成しています。
# unicodedataモジュールをインポートしUnicode文字のプロパティを扱う。
import unicodedata
def lenb(countstring):
"""
文字列の長さをバイト数でカウントする関数
Args:
countstring (str): カウントする文字列
Returns:
int: 文字数での文字列の長さ
"""
length = 0
for char in countstring:
if unicodedata.east_asian_width(char) in 'FWA':
length += 2 # 2バイト文字の場合、2を加算
else:
length += 1 # 1バイト文字の場合、1を加算
return length
def leftb(string, num_bytes):
"""
ExcelのLeftB関数 互換
指定されたバイト数に基づいて文字列の左側から文字を抽出します。
Unicodeの文字幅を考慮し、各文字が占めるバイト数を計算します。文字が途中で切れる場合は、スペースを追加してバイト数を満たします。
Args:
string (str): 対象となる文字列。
num_bytes (int): 抽出するバイト数。
Returns:
str: 指定されたバイト数に基づいて抽出された部分文字列。
"""
byte_count = 0 # 現在のバイト数を追跡する変数
result = [] # 結果を格納するリスト
for char in string:
# バイト数計算
next_byte_count = byte_count + 2 if unicodedata.east_asian_width(char) in 'FWA' else byte_count + 1
if next_byte_count > num_bytes:
# 次の文字が2バイトでバイト数を超える場合、スペースを追加
if next_byte_count - byte_count == 2 and byte_count < num_bytes:
result.append(' ')
break # バイト数の上限に達したため、ループを終了
# 結果リストに文字を追加し、バイト数を更新
result.append(char)
byte_count = next_byte_count
# リストを文字列に変換して返す
return ''.join(result)
def rightb(string, num_bytes):
"""
ExcelのRightB関数 互換
指定されたバイト数に基づいて文字列の右側から文字を抽出します。
各文字が占めるバイト数を考慮し、文字が途中で切れないようにスペースを追加する場合があります。
Args:
string (str): 対象となる文字列。
num_bytes (int): 抽出するバイト数。
Returns:
str: 抽出された部分文字列。
"""
byte_count = 0 # 抽出された文字の合計バイト数を保持する変数
result = [] # 結果を格納するためのリスト
# 文字列を逆順にして、各文字を処理
for char in reversed(string):
# バイト数計算
next_byte_count = byte_count + 2 if unicodedata.east_asian_width(char) in 'FWA' else byte_count + 1
# 次の文字を追加するとバイト数を超える場合、ループを抜ける
if next_byte_count > num_bytes:
# 次の文字が2バイトでバイト数を超えるが、まだ空間がある場合、スペースを追加
if next_byte_count - byte_count == 2 and byte_count < num_bytes:
result.append(' ')
break
# 結果リストに文字を追加し、バイト数を更新
result.append(char)
byte_count = next_byte_count
# リストを逆順にして文字列に変換し返す
return ''.join(reversed(result))
def midb(string, start_byte, num_bytes):
"""
excel MidB関数 互換
指定されたバイト位置から始まり、指定されたバイト数に基づいて文字列の中央から文字を抽出します。
各文字が1バイトか2バイトかを判定します。文字が途中で切れる場合は、スペースを追加してバイト数を満たします。
Args:
string (str): 対象となる文字列。
start_byte (int): 抽出を開始するバイト位置。
num_bytes (int): 抽出するバイト数。
Returns:
str: 抽出された部分文字列。
"""
# 全体の文字数を取得
intlength = lenb(string)
# 開始文字位置まで切り出し
result = rightb(string, intlength - start_byte + 1)
# 開始文字位置から必要文字切り出し
result = leftb(result, num_bytes)
# 文字列を返す
return result
##############################################################
# 関数のテスト
if __name__ == "__main__":
# leftbテストコード
print("leftb-----")
print("[" + leftb("123456", 3) + "]") # '123'
print("[" + leftb("123456", 4) + "]") # '123 '
print("[" + leftb("123456", 5) + "]") # '1234'
print("[" + leftb("123456", 6) + "]") # '1234 '
print("[" + leftb("123456", 9) + "]") # '123456'
print("[" + leftb("123456", 10) + "]") # '123456'
print("[" + leftb("Hello, world!", 6) + "]") # 'Hello,'
print("[" + leftb("Hello, world!", 7) + "]") # 'Hello, '
# rightbテストコード
print("\nrightb----")
print("[" + rightb("123456", 4) + "]") # '56'
print("[" + rightb("123456", 5) + "]") # ' 56'
print("[" + rightb("123456", 7) + "]") # '3456'
print("[" + rightb("123456", 9) + "]") # '123456'
print("[" + rightb("123456", 10) + "]") # '123456'
print("[" + rightb("Hello, world!", 6) + "]") # 'world!'
print("[" + rightb("Hello, world!", 7) + "]") # ' world!'
# midbテストコード
print("\nmidb------")
print("[" + midb("123456", 2, 4) + "]") # '234'
print("[" + midb("123456", 4, 3) + "]") # '4 '
print("[" + midb("123456", 1, 7) + "]") # '12345'
print("[" + midb("123456", 5, 5) + "]") # ' 56'
print("[" + midb("123456", 3, 8) + "]") # '3456 '
print("[" + midb("Hello, world!", 7, 5) + "]") # ' worl'
print("[" + midb("Hello, world!", 4, 8) + "]") # 'lo, worl'
print("[" + midb("Hello, world!", 100, 8) + "]") # ''
print("[" + midb("Hello, world!", 4, 100) + "]") # 'lo, world!'
実行結果
leftb-----
[123]
[123 ]
[1234]
[1234 ]
[123456]
[123456]
[Hello,]
[Hello, ]
rightb----
[56]
[ 56]
[3456]
[123456]
[123456]
[world!]
[ world!]
midb------
[234]
[4 ]
[12345]
[ 56]
[3456]
[ worl]
[lo, worl]
[]
[lo, world!]2バイト文字の文字切り出しが2バイト文字の途中だった場合には半角スペースで埋められます。
最後に
Pythonでは標準でleftb,rightb,midb関数のような関数は提供されていませんがunicodedataモジュールで1バイト2バイト判定を行うことで同様の機能を実現することができます。
この処理を利用することにより以下のシチュエーションに対応可能です。
データベースのフィールドサイズ制限: データベースに保存する前に、特定のフィールドサイズに合わせてテキストデータをトリミングする必要がある場合。
テキストの表示制限: UIに表示するテキストが特定のピクセルまたはバイト数を超えないように制限する場合。
レポート生成: 特定のフォーマットやレイアウト要件を満たすために、テキストデータを加工する際に利用します。
ファイル出力: 固定長テキストファイルに出力する際に、各フィールドのバイト数を正確に合わせる必要がある場合。
利用用途に合致する場合に試してみてはいかがでしょうか。

コメント