
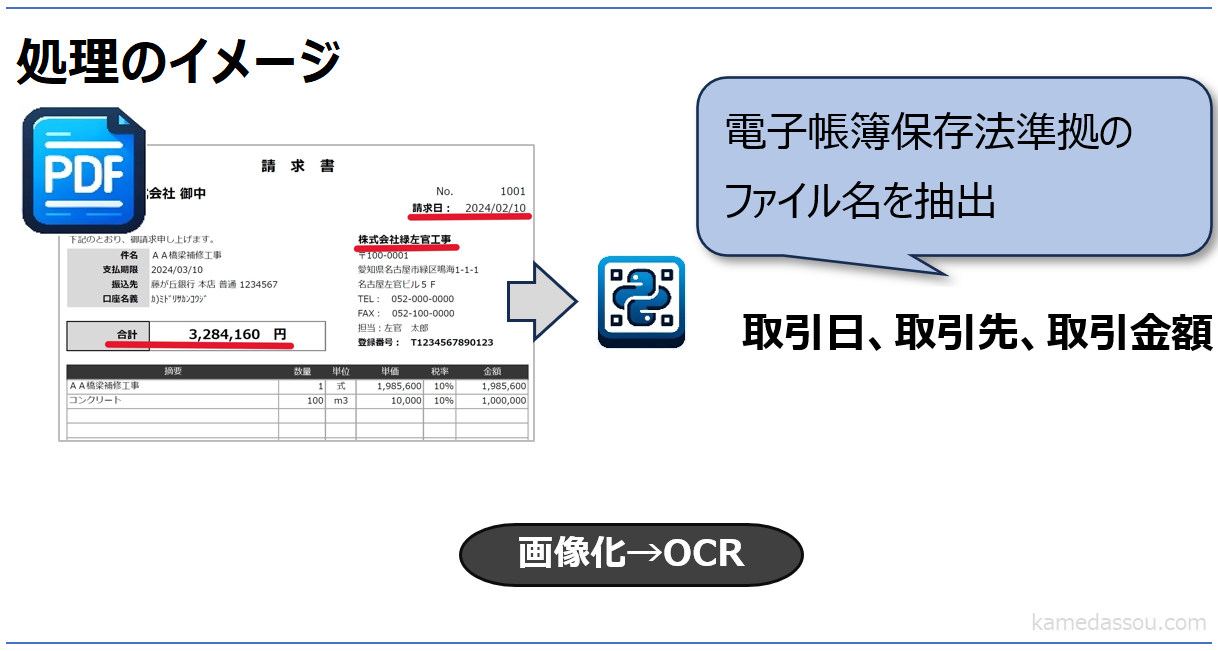
PDFのOCR処理とファイル名生成
PythonではPDFの読み込みや画像のOCR処理、文字列の抽出処理を組み合わせることにより業務運用に合わせたプログラムを作成することが可能です。例えば以下のような業務利用が想定できます。
電子帳簿保存法に対応
メールで受信した請求書のPDFファイルを読み込みして、読み込みした取引日、取引先、取引金額のファイル名を自動取得する。
領収書管理
スキャンした領収書やレシートの画像からOCRを用いてテキスト情報を抽出し経費精算のプロセスを自動化。
レポート自動生成
複数のPDFから文字データを抽出し集計してデータ自動生成。
この記事ではバッチ処理等で請求書PDFファイル読み込みして電子帳簿保存法に準拠したファイル名を取得するという運用を想定して、その方法を説明します。
構築手順について
この記事では以下の順に構築しサンプルコードの動作確認まで行います。
- popplerをインストールする: PDF文書を操作するためのオープンソースのライブラリをインストールします。
- Tesseract-OCRをインストールする: 画像内のテキストを読み取りそれを編集可能なテキスト形式に変換するためのオープンソースソフトウェアライブラリをインストールします。
- 環境変数PATHを設定する: popplerとTesseract-OCRのフォルダに環境変数PATHを設定して、Pythonから操作できるようにします。
- Pythonのライブラリをインストールする: popplerとTesseract-OCRをPythonから操作するライブラリをpipでインストールします。
- テスト用の請求書を準備する: 筆者が準備した請求書のPDFを配置します。
- サンプルコードを動かす: 開発環境ができたら、サンプルコードを動かしてみます。
popplerをインストールする
以下リンクをクリックしてpopplerのRelease-23.11.0-0.zipファイルをダウンロードします。
https://github.com/oschwartz10612/poppler-windows/releases/
※ファイル名はバージョンアップされた場合、異なる場合があります。
popplerとは?
Popplerは、PDFファイルを操作するためのオープンソースのソフトウェアツールです。具体的には、PDFファイルの表示、テキスト抽出、画像抽出などの機能を提供しています。
このライブラリは、プログラミングでPDFファイルを扱いたい開発者にとって便利なツールであり、多くのPDFビューアーやその他のアプリケーションで利用されています。たとえば、PDF文書からテキストや画像を抽出して、他のフォーマットに変換するプログラムを作る時にPopplerが活用されます。
PopplerはC++で書かれており、いくつかのプログラミング言語のバインディングも提供されているため、さまざまな言語で簡単に使用することができます。
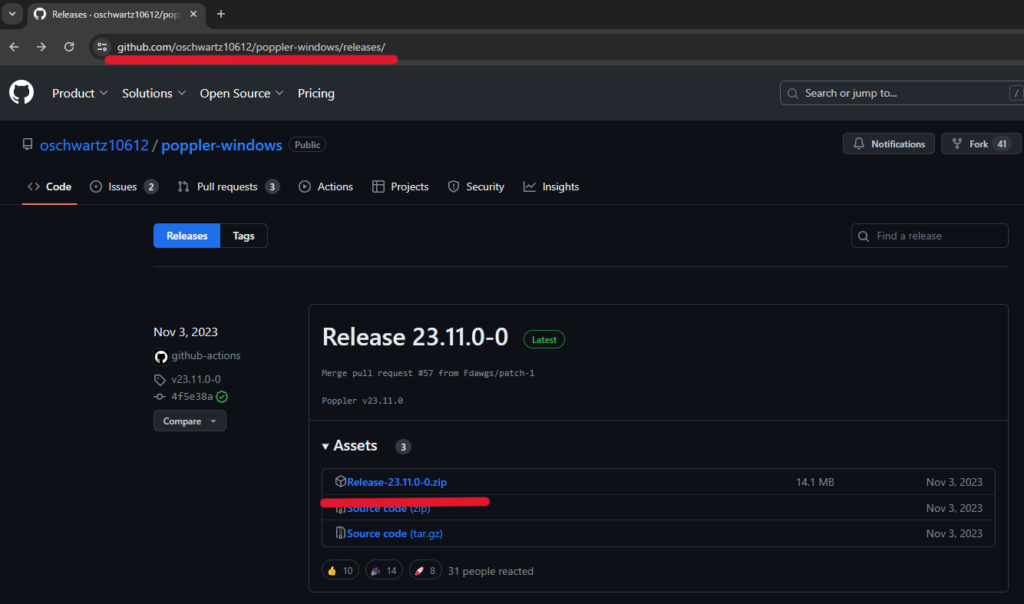
ダウンロードフォルダにファイルがダウンロードされるので、すべて展開して解凍します。
解凍されるのでわかりやすく名前を変更します。筆者の場合はpopplerフォルダとしました。
Cドライブ直下にコピーします。
これで、popplerをインストールするが完了します。
Tesseract-OCRをインストールする
以下リンクをクリックします。
https://github.com/tesseract-ocr/tessdoc
Tesseract-OCRとは?
画像の中から文字を認識してテキストデータに変換するためのオープンソースソフトウェアです。OCRとは「Optical Character Recognition/Reader」の略で、日本語では「光学文字認識」と呼ばれています。この技術は、スキャンされた文書や写真の中の文字を読み取り、編集可能なテキストファイルとして出力することができます。
Tesseract-OCRは、1985年にHP(ヒューレット・パッカード)で開発が始まり、2006年からはGoogleが開発を支援しています。多言語に対応しており、100以上の言語で利用することができます。また、日本語を含む多くの言語で非常に高い認識精度を持っているため、世界中で広く使われています。
このソフトウェアは、書類のデジタル化、自動データ入力、アーカイブの検索可能化など、さまざまな用途で活用されており、プログラマーが自分のプロジェクトやアプリケーションに組み込むことができるようになっています。
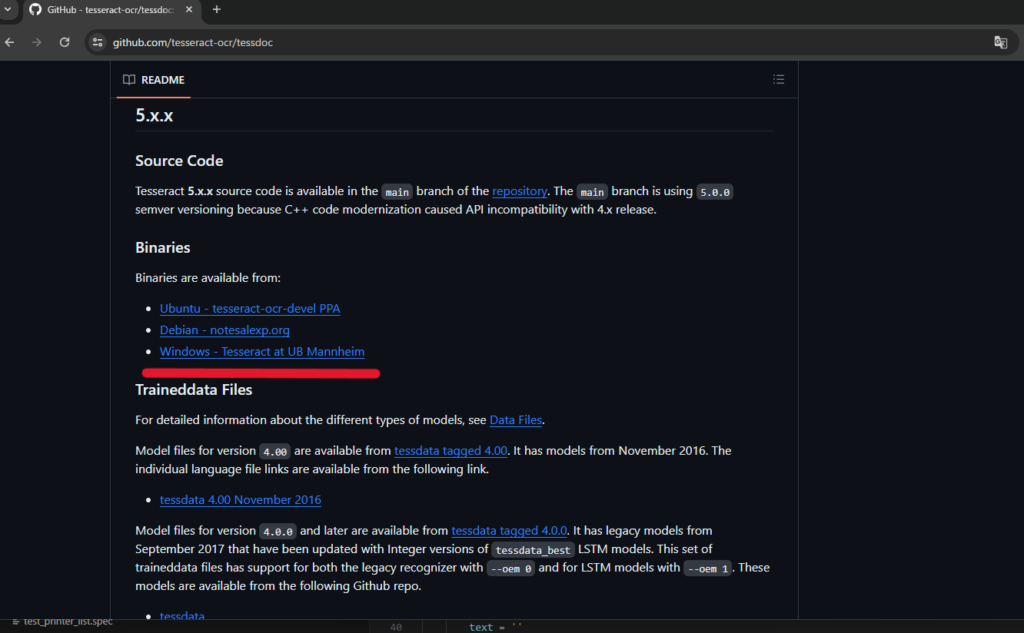
画面下に、スクロールして「Windows – Tesseract at UB Mannheim」をクリックします。
tesseract-ocr-w64-setup-5.3.3.20231005.exeをクリックしてダウンロードします。
※ファイル名はバージョンアップされた場合、異なる場合があります。
ダウンロードされたファイルをダブルクリックしてインストールします。
インストールが進行します。
言語はデフォルトのEnglishを選択して【OK】を押下します。
【Next>】を押下します。
【I Agree】を押下します。
【Next>】を押下します。
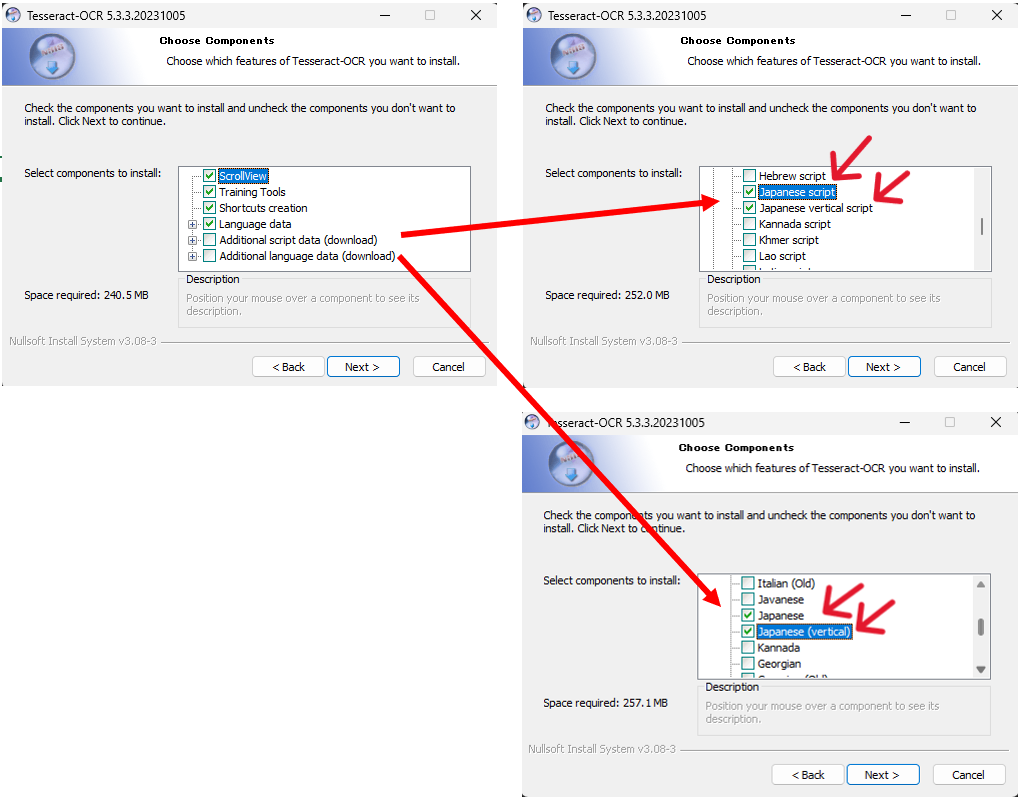
以下画像を参考にしてAdditional script data (download)とAdditional language data (download)の2つの要素に日本語のオプションを設定します。※計4か所チェックをいれます。
インストール先を聞かれるので、環境変数PATHを設定しやすいように「C:¥Tesseract-OCR」に変更します。※環境変数PATHの設定がわかっている方は初期値でも構いません。
【Next>】を押下します。
【Install】を押下します。
【Next>】を押下します。
インストールが完了したので【Finish】を押下します。
これで、Tesseract-OCRをインストールするが完了となります。
環境変数PATHを設定する
popplerとTesseract-OCRのフォルダに環境変数PATHを設定して、Pythonから操作できるようにします。
PCを右クリックして、プロパティを選択します。
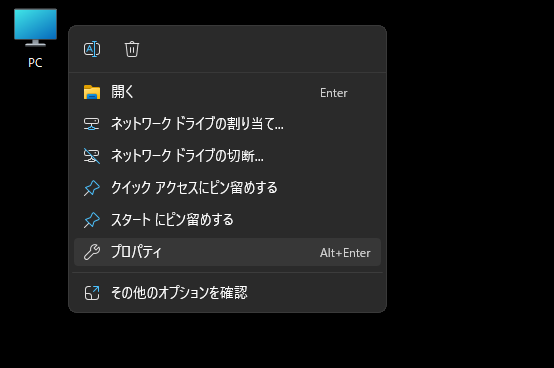
システムの詳細設定を押下します。
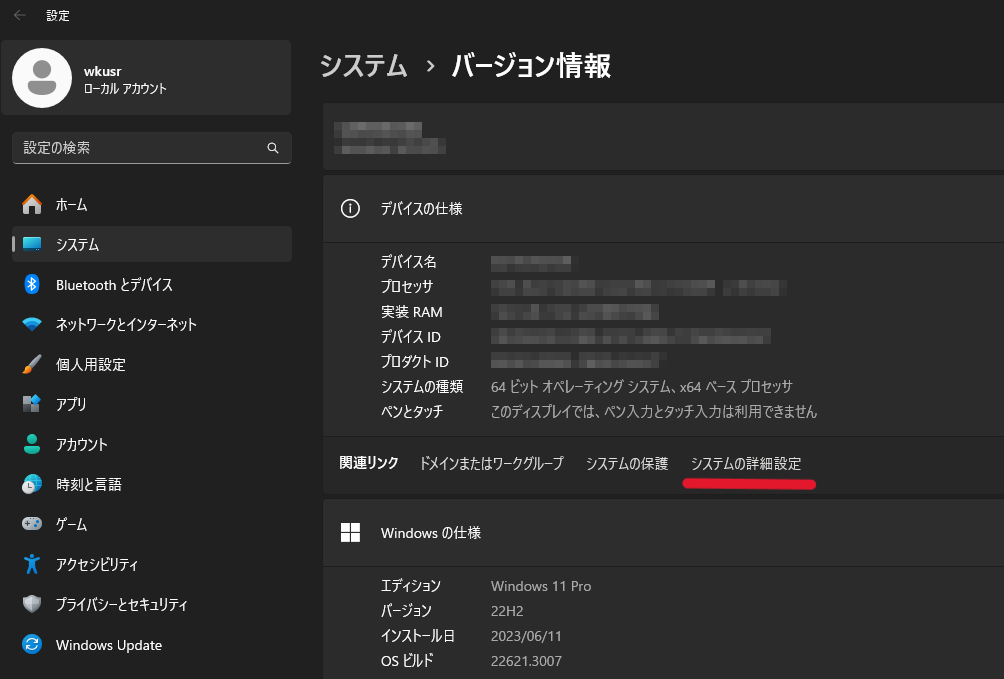
システム環境変数>Pathをダブルクリックします。
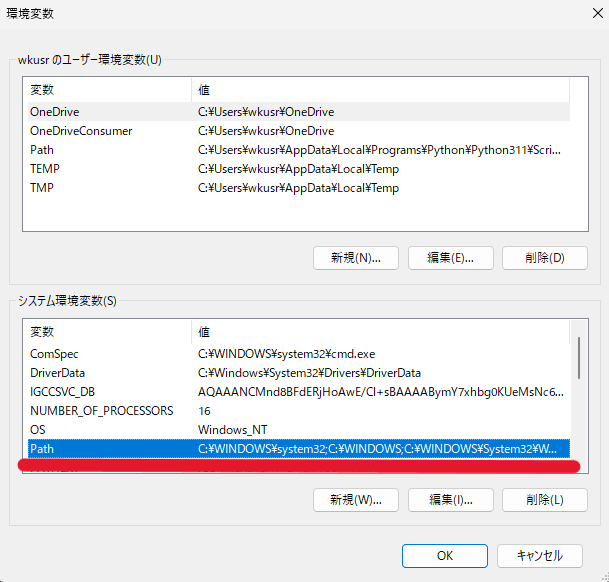
【新規】ボタンを押下して以下2つを追加します。
C:\Tesseract-OCR
C:\poppler\Library\bin
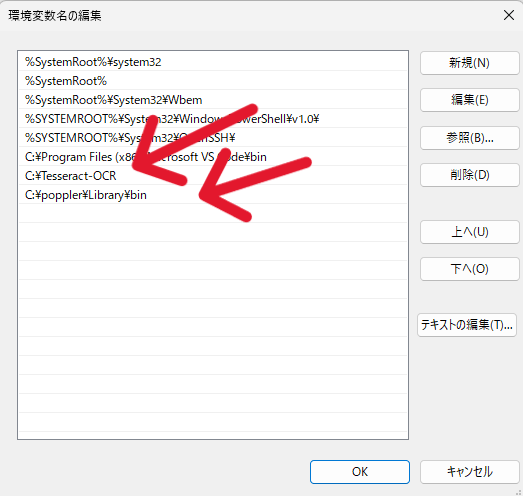
これで、環境変数PATHを設定するが完了となります。
Pythonのライブラリをインストールする
popplerとTesseract-OCRをPythonから操作するライブラリをpipでインストールします。
コンソールからpipコマンドでpdf2imageとpytesseractをインストールします。
pip install pdf2image
pip install pytesseractこれで、Pythonのライブラリをインストールするが完了となります。
テスト用の請求書を準備する
筆者が準備した請求書のPDFを配置します。
以下からtestinvoicepdf.zipをダウンロードします。
zipファイルを解凍してcドライブ直下にtestinvoicepdfフォルダごと配置します。
※invoice.xlsxはプログラムでは利用しませんが金額変更やレイアウト変更したい場合に活用下さい。
変更後はEXCELのファイル>エクスポート>【PDF/XPSの作成】ボタンで出力先をc:\testinvoicepdfフォルダに配置して保存すると変更されたPDFファイルが作成されます。
これで、テスト用の請求書を準備するが完了となります。
サンプルコードを動かす
以下サンプルコードをコピーして貼り付けします。
# pdf2imageをインポート: PDFファイルを画像ファイルに変換するためのライブラリ。
# 事前にpopplerをインストールして、環境変数PATHに追加する必要があります。
# https://github.com/oschwartz10612/poppler-windows/releases/ から Release-xxxxx.zipをダウンロードして展開
# pip install pdf2image
import pdf2image
# pytesseractをインポート: Tesseract-OCRエンジンをPythonから使用するためのライブラリ。
# 事前にTesseract-OCRをインストールして、環境変数PATHに追加する必要があります。
# https://github.com/tesseract-ocr/tessdoc から Windows - Tesseract at UB Mannheim をクリックして tesseract-ocr-w64-setup-xxxxx.exe (64 bit)を展開
# pip install pytesseract
import pytesseract
# tempfileをインポート: 一時ファイルや一時ディレクトリを作成するためのライブラリ。
import tempfile
# OCRで読み込みしたテキストから正規表現で文字列取得用 ※read_pdf関数では未利用
import re
def read_pdf(pdf_path):
"""
PDFファイルをOCRを使用してテキストに変換する関数。
Args:
pdf_path (str): 変換したいPDFファイルのパス。
Returns:
str: OCRにより変換されたテキスト。
"""
# ※PDFから画像への変換時に生成される一時ファイルを保存。
with tempfile.TemporaryDirectory() as path:
# PDFファイルを画像に変換。
pdfimage = pdf2image.convert_from_path(pdf_path, output_folder=path)
# 変換された画像からテキストを抽出し、結果を結合するための空文字列を初期化。
text = ''
# 変換された画像のリストをループ処理。
for img in pdfimage:
# 画像からテキストを抽出、lang='jpn'オプションで日本語指定。
text += pytesseract.image_to_string(img, lang = 'jpn')
# 変換されたテキストを返す。
return text
def read_ocr_text(text):
"""
指定されたテキストから電子帳簿保存法用の取引日、取引先、取引金額を取得します。
Args:
text (str): 数値を抽出する対象のテキスト。
Returns:
file_name (str): ファイル名を返す。取引日_取引先_取引金額
"""
file_name = ""
##### 請求日の取得 #####
# 「請求日:」の位置を見つける
start_index = text.find("請求日:") + len("請求日:")
# 次の改行コードの位置を見つける
end_index = text.find("\n", start_index)
# 起点から改行コードまでの文字列を取得
result = text[start_index:end_index].strip()
# 「/」を除く
result = result.replace('/', '')
# print("請求日:"+ result)
# ファイル名をつける
file_name = result
##### 取引先の取得 #####
# 「上げます。」の位置を見つける
start_index = text.find("上げます。") + len("上げます。")
# 次の改行コードの位置を見つける
end_index = text.find("\n", start_index)
# 起点から改行コードまでの文字列を取得
result = text[start_index:end_index].strip()
# print("取引先:"+ result)
# ファイル名をつける
file_name += "_" + result
##### 合計の取得 #####
# 「合計」から「円」までのパターンを探す正規表現。
pattern = r"合計\s+([\d,.]+)\s*円"
# 正規表現でテキストを検索
match = re.search(pattern, text)
# マッチした場合、数字のみを取得し整数型に変換
result = ""
if match:
# 数字のみを取得
result = ''.join(re.findall(r'\d', match.group(1)))
# print("合計:"+ result)
# ファイル名をつける
file_name += "_" + result
return file_name
##############################################################
# 関数のテスト
if __name__ == "__main__":
# PDFファイルのパスを指定。
pdf_path = "C:\\testinvicepdf\\invoice.pdf"
# pdf_to_text関数を呼び出し、指定されたPDFファイルからテキストを抽出。
extracted_text = read_pdf(pdf_path)
# 請求日、合計、取引先を取得してファイル名とする
file_name = read_ocr_text(extracted_text)
print("#############################################################")
print("ファイル名:" + file_name + ".pdf")
# OCR化されたテキストをすべて出力。
print("#############################################################")
print(extracted_text)
read_pdf関数でinvoice.pdfを画像化→画像をOCRした後でread_ocr_text関数でテキストからファイル名を生成するサンプルコードとなっています。
実行結果
実行をするとPDFファイルを読み込みして電子帳簿保存法に準拠したファイル名を自動生成します。またOCRで読み込みしたPDFのすべての結果を表示します。
#############################################################
ファイル名:20240210_株式会社緑左官工事_3284160.pdf
#############################################################
青空建設株式会社 御中 No. 1001
請求日: 2024/02/10
下記のとおり、御請求申し上げます。 株式会社緑左官工事
件名 AA橋梁補修工事 〒100-0001
支払期限 2024/03/10 愛知県名古屋市緑区鳴海1-1-1
振込先 藤が丘銀行 本店 普通 1234567 名古屋左官ビル5F
口座名義 カミド見か9 TEL: 052-000-0000
FAX: 052-100-0000
スュ 担当 : 左官 太朗
合計 3.284,160 円 登録番号 : T1234567890123
AA橋梁補修工事 1| 式 1.985,600| 109% 1.985,600
コンクリート 100| m3 10.000| 109% 1.000,000
※は軽減税率対象 2.985,600
税率別内訳 税抜金額 消費税額 298,560
10%対象 2,985,600 298,560 3,284,160
軽減896対旬 0 0
0%対象 0 0
備考
工事番号 : 202305671電子帳簿保存法では、電子で取得した請求書等を保存する際に取引日、取引先、取引金額で検索できることが要件となっているので、以下の図のように請求日(取引日)、会社名(取引先)、合計(取引金額)として「ファイル名:20240210_株式会社緑左官工事_3284160.pdf」を生成しています。
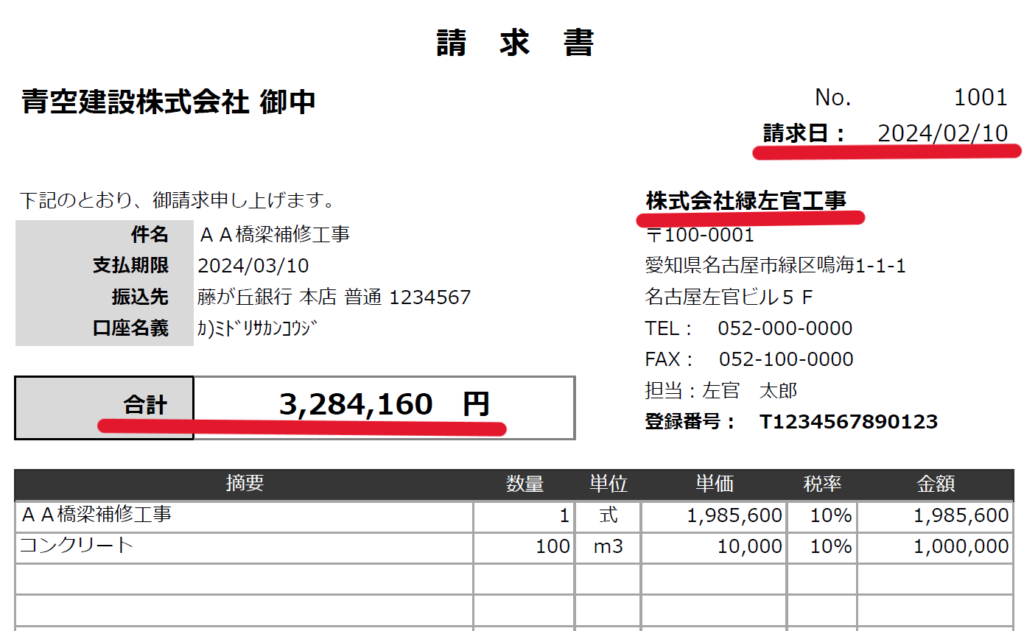
OCRを読み込みすると、例えば合計の例のように「3.284,160」のように整数で取得できない場合もあるので業務運用上はテキスト読み込み処理するread_ocr_text関数は読み込み回数を増やして試行することと、正しいファイル名であるかヒューマンチェックが必要です。
最後に
以上がPDFのOCR処理と電子帳簿保存法準拠のファイル名自動生成する方法です。プログラムを変更することで、いろいろと業務への応用が利くと思いますので参考にしてみてください。
筆者は指定請求書を添付ファイル付きメール受信して、本プログラムサンプルのように自動ファイル命名処理をしています。添付ファイル付きメールの受信については以下の記事がありますのでこちらも参考にしてみてはいかがでしょうか。


コメント